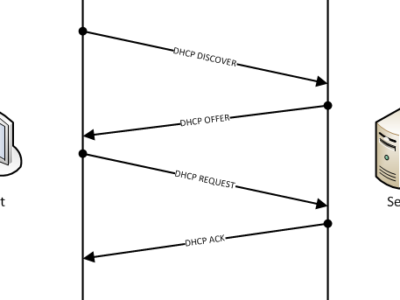
4.6 Бесклассовые сети (CIDR), маска подсети/сети переменной длины (VLSM) в протоколе IP
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать основы работы компьютерных сетей и протокол сетевого уровня IP, а если быть более точным, то его версию IPv4. В бесклассовых IP сетях используется маска подсети/сети переменной длины и работает два механизма: CIDR и VLSM. Бесклассовые сети являются прямой линией развития от классовых сетей, их преимущество заключается в том, что они позволяют экономнее расходовать пул IPv4 адресов. О том за счет чего это происходит, мы поговорим в этой теме.
Если тема компьютерных сетей вам интересна, то можете ознакомиться с другими записями курса.
Оглавление первой части: «Основы взаимодействия в компьютерных сетях».
Оглавление четвертой части: «Сетевой уровень: протокол IP и его версия IPv4».
Содержание статьи:
- 1 4.6.1 Введение
- 2 4.6.2 CIDR или механизм бесклассовых IP сетей
- 3 4.6.3 VLSM или маска переменной длины в IP сетях
- 4 4.6.4 Как узнать номер сети и как определить номер узла
- 5 4.6.5 Как разделить сеть на подсети
- 6 4.6.6 Все возможные маски подсети переменной длины
- 7 4.6.7 Дырявые или обратные маски (Wildcard mask)
- 8 4.6.8 Специальные маски
- 9 4.6.9 Выводы
4.6.1 Введение
Понимание принципа работы механизмов CIDR и VLSM, а также выбор и расчет маски подсети переменной длины — это ключевой момент в современных IPv4 сетях, без понимания которого будет трудно и неприятно работать, работа всегда неприятна, если она не понятна. Поэтому давайте избавимся от все неприятных моментов и детально разберемся с этим вопросом. Тема очень большая и для ее понимания рекомендую, как минимум, повторять примеры самостоятельно.
4.6.2 CIDR или механизм бесклассовых IP сетей
CIDR (Classless Inter-Domain Routing) – это гибкий метод IP-адресации в компьютерных сетях, который позволяет экономить адресное пространство, данный метод снимает ограничение классовых сетей, которое заключалось в том, что конкретный IP-адрес принадлежал конкретному классу, а это означало, что этому IP-адресу соответствовала маска фиксированной длины, строго закрепленная за классом.
В общем, мы поумничали, теперь давайте разбираться, ибо много умничать – плохо. В чем была проблема классовых сетей, да в том, что они не позволяли создавать маленькие сети. Давайте посмотрим на примере: у нас есть локальная сеть из 6 компьютеров, подключенных к коммутатору, нам нужно, чтобы эти компьютеры могли взаимодействовать между собой. Как нам быть, если используется классовая адресация. Всё просто: нужно взять одну любую сеть из класса C и раздать IP-адреса из этой сети нашим компьютерам, это наглядно продемонстрировано на Рисунке 4.6.1.
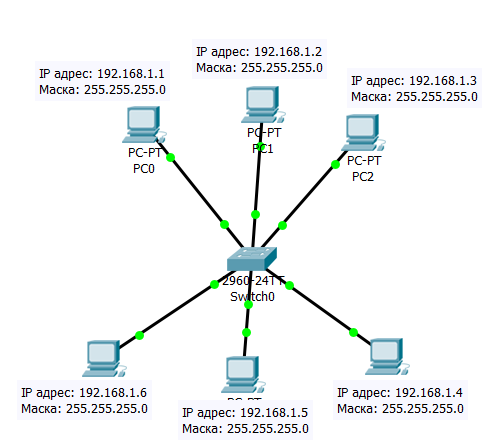
Рисунок 4.6.1 Сеть из шести узлов, в которой используется классовая адресация
Почему сеть класса C? Да потому что это самый маленький диапазон IP-адресов, который возможен в классовых сетях, но, постойте, зачем нам сеть, в которой 256 IP-адресов, ведь она дает возможность включить 254 узла (ведь один IP-адрес уйдет на номер сети, а другой будет широковещательным и их нельзя выдавать узлам), а у нас их всего шесть! А вдруг за эти IP-адреса нужно будет кому-то платить, а зачем нам платить за 256 адресов, когда нам нужно 6 адресов? Правильно, не зачем, мы маленькая российская компания, которая никогда не вырастет, нам не нужно столько адресов, у нас нет столько денег! А если взглянуть на ситуацию немного иначе. Допустим, в мире нет никаких частных IP-адресов, все адреса являются публичными, мы маленькая компания, сотрудник которой приходит к окошку, в котором сидит тетенька, выдающая IP-адреса по справкам с 14:00 до 15:00 только по средам и пятницам. А в мире до сих пор используются классовые сети. Мы приходим со справкой, в которой написано: нужно 6 IP-адресов. Тетенька читает эту справку и говорит: нет, не дам я вам IP-адреса, потому что их и так мало, да и выдать я могу вам только 256 адресов, и вообще у меня в инструкции написано: выдавать IP-адреса только тем, у кого в сети больше 200 узлов, а то на всех не хватит.
То есть не экономность классовых сетей весьма ощутима, даже если в нашей сети два узла, мы в любом случае вынуждены использовать сеть, которая, как минимум, рассчитана на 254 узла. Не забываем, что классы у нас фиксированные и маски в этих классах так же фиксированные. Получается, что нужно отказываться от классов и фиксированных масок. И это действительно произошло, появились бесклассовые сети или CIDR, принцип работы, которых основан на масках переменной длины или VLSM (variable length subnet mask). А это уже гибкий механизм, который позволяет выделять пулы IP-адресов почти такого размера, как нам хочется. Давайте посмотрим на Рисунок ниже, допустим наша компания каким-то чудом расширилась и появился седьмой сотрудник, его надо обеспечить рабочим местом.
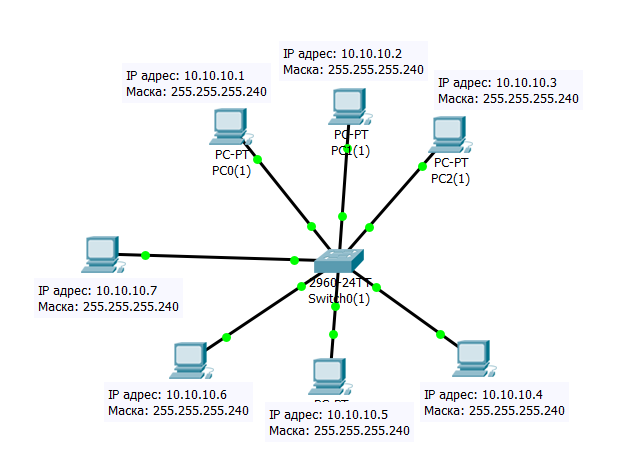
4.6.2 Сеть из семи узлов, в которой используется маска переменной длины
Заметили? Мы используем IP-адрес из сети класса А, но почему-то у нас какая-то странная маска: 255.255.255.240. А это всё благодаря CIDR и VLSM, который позволяет отказаться от классов и фиксированных масок, теперь мы можем использовать любые IP-адреса с любыми масками, но для масок все равно должно выполняться условие: сначала идут только единицы, а потом только нули. Те, кто уже перевел IP-адрес и маску в двоичный вид, понял, что номер сети здесь 10.10.10.0, broadcast адрес 10.10.10.15, а адреса между ними можно использовать на узлах нашей сети, то есть маска 255.255.255.240 позволяет пронумеровать 14 узлов. Но у нас их семь, разве нельзя подобрать маску, чтобы сделать сеть на семь узлов? Ответ, нет! Нельзя, я сразу сказал, что VLSM позволяет нарезать сети почти такого размера, как нам нужно.
Весь затык в маске, а именно в требование, что сперва должны быть только единицы, которые определяют номер сети, а потом должны быть нули, которые определяют часть IP-адреса, используемую под номера хостов/узлов. Следующая маска, которая удовлетворяет условию единиц и нулей выглядит так: 255.255.255.248, если ее наложить на IP-адрес из нашей сети, то получится, что номер сети 10.10.10.0, адрес широковещательной рассылки 10.10.10.7, а под номера узлов у нас остается только шесть IP-адресов, и зачем мы только нанимали седьмого сотрудника, так бы могли взять маску 255.255.255.248. Плюсы бесклассовых сетей очевидны, давайте погружаться в детали.
4.6.3 VLSM или маска переменной длины в IP сетях
VLSM (variable length subnet mask) или маска подсети переменной длины – это основа, на которой строятся бесклассовые сети, именно благодаря тому, что появилась возможность использования масок переменной длины и произошел отказ от классов, мы до сих пор пользуемся протоколом IPv4, адреса которого уже практически исчерпаны, но еще не до конца.
Теперь нам нужно стать рыбкой, а именно нам нужно забыть о том, что существуют классы и о том, что каждому классу соответствует фиксированная маска. Классов нет, маска может быть любой, только не забывайте про правило нулей и единиц. Но теперь стало немного труднее рассчитывать сети, раньше-то маски были фиксированные, более того, старые маски проводили четкую границу в IP-адресе между номером сети и номером узла, эта граница при любом классе находилась между октетами IP-адреса, а теперь какие-то непонятные маски, да еще и граница может находиться где-то внутри октета, давайте разбираться с этим VLSM, всё не так страшно.
Представим, что у нас есть сеть на два узла, это значит, что маска должна быть такой, которая позволяет иметь четыре IP-адреса. Два адреса уйдут на номер сети и широковещательную рассылку, а два адреса мы дадим своим узлам. Давайте теперь поразмыслим и выпьем чаю. Раз нам нужно только четыре адреса, то это 100% гарантия, того, что первых три октета маски должны быть единицами: 255.255.255.x, в двоичной системе счисления это выглядит так: 11111111 11111111 11111111 xxxxxxxx. Ну, пол дела сделано. Осталось разобраться с последним октетом. Что мы знаем изначально? Мы знаем то, что нам нужно два IP-адреса на узлы, то есть между этими адресами разница должна быть всего в один бит, а еще мы помним, что в маске сперва идут только нули, а затем только единицы, пока всё логично.
Руководствуясь этой логикой можно сделать вывод о том, что IP-адреса должны отличать только лишь значением последнего бита, то есть наша маска должна содержать сперва 31 единицу и последний ноль, тогда получится выделить ровно два IP-адреса, в десятичной системе счисления такая маска будет выглядеть так: 255.255.255.254, в двоичной она примет такой вид: 11111111 11111111 11111111 11111110. Хорошо говорим мы, но первый IP-адрес у нас должен уйти на номер сети, а последний широковещательный, их нельзя давать узлам, ничего не будет работать! И в какой-то мере мы правы, но такая маска имеет специальное назначение, и она будет работать в некоторых случаях, но об это в конце данной темы, сейчас нам нужно искать выход!
Чтобы его найти, нам нужно помнить про нули и единицы в маске, и внимательно посмотреть на то, что мы получили ранее: 11111111 11111111 11111111 11111110. Смотрите, последний бит в этой маске у нас ноль, этот ноль говорит о том, что последний бит IP-адреса может меняться, а первых 31 бит должны оставаться неизменными, то есть такая маска допускает наличие в подести двух IP-адресов, так как система счисления у нас двоичная, один бит мы можем изменять и этот один бит может принимать только два значения: 0 и 1, следовательно, справедлива вот такая формула: 21 = 2. В выражение двойка, которую мы возводим в степень – это основание двоичной системы счисления, эту двойку мы возводим в первую степень, потому что у нас для номера узла есть только один бит.
Из всего вышеописанного следует, что нам ничего не остается, кроме как взять и забрать один бит из номера сети и отдать его под номер узла, как мы это можем сделать? Правильно! Обнулить предпоследний бит маски подести, для такой ситуации будет действовать формула 22 = 4. Раз теперь мы можем изменять два последних бита IP-адреса и значение у нас только два, то получается, что два нужно возвести во вторую степень, чтобы узнать количество доступных IP-адресов. Тогда у нас будет такая маска: 11111111 11111111 11111111 11111100, в десятичной системе счисления она будет выглядеть так: 255.255.255.252. Что будет, если мы обнулим у маски третий бит с конца, да всё очевидно, будет формула 23 = 8, а это значит, что такая маска выделяет нам восемь IP-адресов, при этом два IP-адреса уйдут на номер сети и broadcast, а шесть адресов будут в нашем распоряжении для нумерации узлов.
Заметили тенденцию? Мы можем определить количество IP-адресов, которые нам вырезает маска просто считая нули в конце и используя нашу формулу. Так, например, самая большая маска, которую можно использовать 11111111 11111111 11111111 11111111 или 255.255.255.255, тут нулей нет, значит наша формула примет такой вид: 20 = 1 и действительно, такая маска позволяет «выкусить» из общего пула только один IP-адрес, а самая маленькая маска у нас такая 0.0.0.0, то есть все 32-а бита имеют значение ноль, тогда формулка будет: 232 = 4 294 967 296.
Вот такую гибкость мы получаем в классовых сетях балгодаря механизмам CIDR и VLSM, маска переменной длины позволяет выкусывать и резать сети на подсети очень гибко. Также рекомендую вспомнить вам структуру IP-пакета, в его заголовке нет поля для маски подсети и она не передается по сети. Маску подсети используют конечные устройства (клиентские и серврерные компьютеры, можете почитать о взаимодействие клиент-сервер) и транзитные устройства (умные коммутаторы и маршрутизаторы, хабы сюда отнести нельзя, так как они работают на физическом уровне и оперируют битами, но никак не IP-пакетами), чтобы понять: принадлежит ли пакет к их подсети или нет на конечных устройствах, а транзитные используют маски, когда пытаются понять в каком направлении будет выгоднее всего отправить пришедший пакет.
4.6.4 Как узнать номер сети и как определить номер узла
До этого мы говорили о маске подсети абстрагировано от IP-адреса, давайте теперь перейдем к конкретике и посмотрим, как маска подсети переменной длины позволяет определять по IP-адресу где там номер сети, а где номер узла. В бесклассовых сетях одного IP-адреса недостаточно, чтобы понять, где номер сети, а где номер узла, здесь обязательно нужна VLSM.
Для примера возьмем IP-адрес 137.98.16.45 и маску 255.255.255.192. Какие выводы мы можем сделать сразу? А можем мы сделать выводы сразу о том, что к номеру сети точно относится вот эта часть IP-адреса: 137.98.16.x, остается только понять, что скрывается за этим «х»? Переведем в двоичную систему счисления и IP-адрес, и маску целиком.

Рисунок 4.6.3 Переводим IP-адрес и маску подсети в двоичную систему счисления
Итак, результат перед вами в таблице выше, надеюсь, многим из вас, как и мне, проще сперва увидеть логику вычислений, а не читать длинные объяснения, и меня простят за то, что я сперва показал результат, а затем объясняю:
- Сначала переводим IP-адрес в двоичную систему счисления и выписываем его в таком виде.
- Затем переводим маску подсети в двоичную систему счисления и записываем ее под IP-адресом.
- Затем накладываем маску на IP-адрес, выполняя операцию «Логическое И», руководствуясь следующим правилом: для каждого бита IP-адреса нужно выполнить операцию «Логическое И» с соответствующим битом маски. То есть для первого бита IP-адреса мы выполняем «Логическое И» с первым битом маски, для второго со вторым, для третьего с третьим.
- В результате этой операции мы узнаем номер сети и записываем результат в двоичном виде под маской.
- Для себя отмечаем те биты, которые обнулились в результате наложения маски на IP-адрес (оранжевые нули) и выписываем их в четвертую строку, не изменяя их позиции в октете, но заменяя ноли на единицы (выделены синим), а дальше в соответствие с позициями выписываем все оставшиеся биты IP-адреса, которые не были обнулены после наложения, изменять эти биты не нужно. Так у нас получился широковещательный адрес.
- А чтобы узнать номер узла, нам нужно выписать биты IP-адреса, которые обнулились после наложения маски и перевести их в десятичную систему счисления.
В итоге у нас получилось следующее:
- Номер сети: 137.98.16.0.
- Номер узла в этой сети: 45.
- Широковещательный адрес: 137.98.16.63.
- Первый IP-адрес узла в подсети: 137.98.16.1.
- Последний IP-адрес узла в подсети: 137.98.16.62.
- Общее количество IP-адресов в этой подсети: 64 = 28.
Собственно, путем нехитрых преобразований мы получили всю нужную информацию для настройки рабочих станций в этой подсети. Но у нас вышел удачный пример из-за номера сети. Давайте возьмем пример, в котором номер сети ну будет содержать ноль в последнем октете.
Для примера используем IP-адрес 10.10.10.135 и маску 255.255.255.224. Снова сделаем нашу табличку, но особых пояснений я давать не будут, цифры скажут больше.

Рисунок 4.6.4 Определяем номер сети и номер узла по IP-адресу и маске
Тогда у нас получается следующие характеристики подсети:
- Номер сети: 10.10.10.128.
- Номер узла: 7. Да, конкретно в этой сети номер узла будет 7, в этом легко убедиться: наш IP-адрес 10.10.10.135, а номер сети 10.10.10.128, 135 – 128 = 7.
- Широковещательный адрес в этой сети: 10.10.10.159.
- Первый адрес узла в подсети: 10.10.10.129. Он всегда на единицу больше, чем номер сети.
- Последний адрес узла в подсети: 10.10.10.158. А этот всегда на единицу меньше, чем broadcast.
- Общее количество IP-адресов в подсети: 32. Количество узлов в сети, как правило (за редким исключением) на два меньше.
Как видите, ничего сложного в том, чтобы узнать номер сети и номер узла по известному IP-адресу и маске нет. Нужно только уметь переводить числа из десятичной системы в двоичную и выполнять простую операцию из булевой алгебры.
4.6.5 Как разделить сеть на подсети
Пока все было просто, надеюсь, что так будет и в дальнейшем, сейчас нам нужно научиться разделять сети на подсети, это лишь немного сложнее, чем определять номер сети и номер узла. Давайте смотреть на примере. Перед нами поставлена следующая задача: нам дана сеть с маской 192.168.1.0/24 и сказано, что нужно разделить эту сеть на шесть подсетей: три подсети должны обеспечить по два узла IP-адресами и еще три подсети должны быть одинакового размера. Давайте приступать. Начинать мы будем с маленьких подсетей и переходить к большим.
Стоит дать пояснение к записи 192.168.1.0/24. Это сокращенная форма записи IP-адреса и маски, ее можно было бы заменить на 192.168.1.0 255.255.255.0. Если перевести эту маску в двоичный вид и посчитать количество единиц, то их будет ровно 24, отсюда и запись «/24». Например, если вам дадут такую запись 192.168.1.0/30, то это будет означать: 192.168.1.0 255.255.255.252, ведь в такой маске тридцать единиц.
Перед началом следует дать одно важное замечание: IP-адреса в разных подсетях не должны пересекаться, например, если из нашей сети вы выделите подсеть 192.168.1.48/30, то тогда вы уже не сможете разбить эту сеть на две равные части по маске 255.255.255.128. Получается, что в сеть 192.168.1.48/30 входят IP-адреса с .48 по .41, а в сеть 192.168.1.0/25 входят IP-адреса с .0 по .127, и получается, что IP-адреса в таких диапазонах пересекаются, поэтому разрезать сеть на подсети нужно по порядку, а не выхватывать куски из середины, иначе может оказаться так, что часть IP-адресов вы просто не сможете использовать. Итак, приступим.
Сначала нам необходимо вырезать три маленькие сеточки, которые могли бы обеспечить два узла IP-адресами, то есть это сети, которые включают в себя четыре IP-адреса, хотя давайте представим, что мы этого еще не знаем. Но в этот раз обойдемся без табличек. Просто выпишем исходный IP-адрес и маску в двоичном виде друг под другом.
[php]
11000000 10101000 00000001 00000000
11111111 11111111 11111111 00000000
[/php]
Вот такая конструкция у нас получается, вспоминаем, что число узлов всегда меньше числа IP-адресов в подсети на два, а нам нужно три сети по два узла в каждой, значит нам нужны подсети по четыре IP-адреса, а четыре IP-адреса нам дадут маски, у которых последних два бита нули, а все остальные единицы. Сказано – сделано. Выписываем номер нашей исходной подсети, а под ней записываем маску, у которой только два последних бита нули.
[php]
11000000 10101000 00000001 00000000
11111111 11111111 11111111 11111100
[/php]
Мы получили первую нашу маленькую подсеть, которую в сокращенном виде можно записать как 192.168.1.0/30. В этой подсети номер сети совпадает с номером исходной сети (это предложение вас должно немного озадачить, но чуть позже я дам пояснения), IP-адрес первого узла 192.168.1.1, а широковещательный адрес 192.168.1.3. Таким образом из пула в 256 адресов мы забрали первых четыре адреса. Логично предположить, что номер следующей подсети, как не крути будет таким: 192.168.1.4. Записываем его в двоичном виде и выписываем нашу маску.
[php]
11000000 10101000 00000001 00000100
11111111 11111111 11111111 11111100
[/php]
Получаем все остальные характеристики, но самое важное сейчас для нас то, что broadcast адрес у второй нашей маленькой подсети будет таким: 192.168.1.7, а для нас это означает, что номер следующей подсети вот такой: 192.168.1.8. Повторяем наши нехитрые действия.
[php]
11000000 10101000 00000001 00001000
11111111 11111111 11111111 11111100
[/php]
Смотрим широковещательный адрес: 192.168.1.11. Номер следующей сети будет 192.168.1.12. Но пока это нам мало чего дает. Вспоминаем условия задачи: оставшиеся IP-адреса разделить на три равные части. В нашем исходном пуле было 256 адресов, мы уже забрали 12 (с .0 по .11), считаем 256 – 12 = 244. Ну а 244/3 = 81. Вспоминаем, что количество IP-адресов в подсети определяется количеством нулей в маске по формуле 2n, где двойка – это основание двоичной системы счисления, а n – это количество нулевых бит в маске, выходит, что самое близкое количество IP-адресов, удовлетворяющее условию нашей задачи, равно 64 в каждой из оставшихся подсетей. Поскольку 26 = 64, а 27 =128, второе нам не подходит, так как у нас нет столько IP-адресов. Получается, что 51 IP-адрес из данного нам пула останутся в запасе.
Напомню на чем остановился процесс нарезания нашей сети на подсети, я сказал, что номер следующей подсети будет 192.168.1.12. А мы только что выяснили, что три больших сети у нас будут по 64-е IP-адреса. Ну давайте пробовать откусить 64-е адреса, начиная со 192.168.1.12.
[php]
11000000 10101000 00000001 00001100
11111111 11111111 11111111 11000000
[/php]
Почему у нас в конце маски шесть нулей? Я это уже объяснил: чтобы была возможность выкусить 64-е адреса, нам нужно шесть бит, а значит маска должна быть 255.255.255.192, 192 в двоичной системе: 11000000. Теперь давайте считать:
- Номер сети 192.168.1.0.
- Адрес первого узла 192.168.1.1.
- Широковещательный адрес: 192.168.1.63.
Смысла дальше продолжать нет, мы видим, что с такой маской у нас идет пересечение IP-адресов в разных подсетях, а этого мы допустить не можем, а других масок у нас нет, если опираться на условия задачи. А нули с единицами в маске чередоваться не могут, поэтому бесхозными у нас останутся адреса в середине пула, который нам дали, конечно, для частного диапазона IP-адресов это не критично, для большинства локальных сетей его более чем достаточно и эти адреса можно не экономить. Но, например, есть такие компании, как Яндекс, в одном из их докладов на Ютубе сотрудник Яндекса сказал, что серого диапазона IP-адресов им хватает на полтора дата-центра, а у Яндекса их несколько десятков, поэтому они используют публичные IPv6 адреса, которых по нынешним меркам более чем достаточно, чтобы не экономить, но это пока.
Мы уже обожглись на молоке, но на воду дуть не будем. Давайте лучше поделим и посчитаем. Итак, нам было дадено 256 адресов и поставлена задача, с первой частью которой мы успешно справились, и начали решать вторую, выяснив, что три сети должны быть по 64-е IP-адреса. Нам сразу нужно было прикинуть, сколько сеток по 64-е адреса поместятся в сеть из 256-ти IP-адресов, для этого нужно просто разделить 256/64 = 4, если бы это сразу сделали, то даже не стали бы пробовать выполнять операцию, приведшую к пересечению, ведь и так ясно, что в сети из 256 адресов может поместиться только четыре сети по 64 адреса и только при том условии, что они будут следовать друг за другом, поэтому нам нужно отбрасывать первую сеть 192.168.1.0/26 и начинать нарезать со второй. Но хотя бы мы уже ранее выяснили, что номер первой большой подсети 192.168.1.64, поэтому:
[php]
11000000 10101000 00000001 01000000
11111111 11111111 11111111 11000000
[/php]
Широковещательный адрес подсети 192.168.1.64/26 будет таким: 192.168.1.127, а значит вторая подсеть на 64-е IP-адреса у нас такая: 192.168.1.128/26, ее broadcast адрес будет таким: 128+63 = 191, то есть 192.168.1.191. Не всегда нужно переводить в двоичную систему счисления, когда вы разделяете сеть на подсети. Стоит объяснить почему мы прибавляли 63. Допустим нам дана сеть 192.168.1.0/26, ее номер уже перед глазами, всего в такой сети 64-е IP-адреса, а отсчет IP-адресов ведется с нуля, значит, нужно просто взять и прибавить к значения самого первого IP-адреса, который является номер подсети, количество оставшихся IP-адресов в сети, то есть 64-1, эта единица, которую мы вычитаем, как раз-таки и есть номер подсети, его учитывать не нужно.
Руководствуясь этой логикой, мы получим третью большую подсеть и ее широковещательный адрес: 192.168.1.192/26 и 192.168.1.255. Таким образом у нас остались не задействованные IP-адреса с 192.168.1.12 по 192.168.1.63 включительно. Пусть это будет нашим запасом, а не просчетом. Давайте из оставшегося диапазона выкусим сеть на 32-а IP-адреса, это будет маска: 255.255.255.224. Для этого выпишем номер исходной сети (192.168.1.0) и эту маску:
[php]
11000000 10101000 00000001 000|00000
11111111 11111111 11111111 111|00000
[/php]
Не забываем, что пересечений с уже занятыми адресами быть не должно, поэтому сеть 192.168.1.0/27 нам не подойдет, так как она дает пересечение. Смотрим на Broadcast этой сети: 11000000 10101000 00000001 000|11111 или 192.168.1.31 в двоичном виде, значит, номер следующей сети: 11000000 10101000 00000001 001|00000 или 192.168.1.32/27, а этот кусок мы уже можем откусить, так как он не даст пересечений, итого у нас получились сети:
- 192.168.1.0/30. Первая маленькая подсеть.
- 192.168.1.4/30. Вторая маленькая подсеть.
- 192.168.1.8/30. Третья маленькая подсеть.
- 192.168.1.32/27. Дополнительная подсеть.
- 192.168.1.64/26. Первая большая подсеть.
- 192.168.1.128/26. Вторая большая подсеть.
- 192.168.1.192/26. Третья большая подсеть.
Теперь мы не используем только диапазон IP-адресов с 192.168.12 по 192.168.1.31, то есть двадцать IP-адресов. Для закрепления материала разделите оставшийся диапазон по маске /29, у но и в этом случае у вас будут неиспользованные IP-адреса, поэтому вам нужно будет определить: какая маска подойдет для этих адресов.
А теперь про то, что нас смутило в самом начале. Наш общий пул адресов имеет такой вид: 192.168.1.0/24, а первая маленькая подсеть 192.168.1.0/30, ну а последняя большая подсеть 192.168.1.192/26. Получается интересная ситуация. Номер нашей общей подсети, которую мы резали на части 192.168.1.0, он совпадает с номером нашей первой маленькой подсети. А широковещательный адрес исходной сети совпадает с широковещательным адресом третье большой подсети 192.168.1.255. И как тут быть, как нашим бедным узлам и маршрутизаторам не запутаться? На самом деле ничего страшного тут нет. В настройках конечного узла мы обычно задаем для него IP-адрес самого узла, адрес шлюза по умолчанию и маску подсети, в которой этот узел находится, на интерфейсах маршрутизаторов мы задаем IP-адрес и маску. И конечные узлы, и маршрутизаторы, сравнивают IP-адрес назначения в получаемых или отправляемых пакетах со своими адресами и масками. Так, например, если узел из подсети 192.168.1.128/26 будет пинговать IP-адрес 192.168.1.255, то для него это будет не широковещательный адрес, а адрес из другой подсети (а значит узел будет отправлять такой пакет на адрес основного шлюза как обычный Unicast), ведь по настроенным на этом узле IP-адресу и маске узел понимает, что широковещательный адрес в его подсети 192.168.1.191 и если попробовать пропинговать этот IP-адрес, то узел отправит сообщение всем участникам канальной среды, в которой он находится.
Но такая идилия была не всегда. Были времена, когда выполнить такое деления, как мы сделали сейчас, было невозможно. Дело в том, что какое-то время маршрутизаторы и узлы поддерживали оба механизма IP-адресации одновременно (и классовую адресацию, и CIDR).
Проблема была в следующем: у нас есть сеть 192.168.1.0/24, которую нам нужно поделить на несколько более мелких сетей, например так, как это сделали мы. Но, адрес 192.168.1.0 – это адрес сети класса C, а мы помним, что сеть класса C сопровождается маской 255.255.255.0, а это значит, что номер такой сети 192.168.1.0, а Broadcast 192.168.1.255. Бедные сетевые железяки поддерживали оба механизма (и VLSM, и классы), иначе мы бы не могли поделить сеть 192.168.1.0/24 на более мелкие куски. И тут действительно возникали проблемы, в том случае, который описан выше, роутеры и узлы просто не могли правильно работать с IP-пакетами из тех сетей, которые были нами описаны.
Другими словами, если вам встретится роутер, который поддерживает оба механизма адресации, и вы захотите разделить сеть на подсети, как это сделали мы, то у вас будет два выхода: либо исключить сети 192.168.1.0/30 и 192.168.1.192/26, либо выключить механизм классовой адресации. О том, как это сделать в роутерах Cisco, мы поговорим в другой теме.
4.6.6 Все возможные маски подсети переменной длины
Как вы могли уже понять масок подсети намного меньше, чем IP-адресов, всё дело в том, что для маски подсети должно выполняться условие: сначала только нули, а затем только единицы, но все дело в том, что не все числа в двоичной системе счисления подходят под это условия, есть числа, у которых 0 и 1 тем или иным образом чередуются, также есть числа такие, как 240, если его представить в двоичном виде, что оно будет записано так: 11110000, такое число можно использовать в маске, но оно должно быть в том октете, который проводит границу между номером сети и номером узла. Например, 255.240.255.0 недопустимое значение маски, т.к. здесь идет чередование нулей и единиц, а вот такие маски возможны: 255.255.255.240, 255.255.240.0, 255.240.0.0, 240.0.0.0. Из-за этих двух факторов, число масок переменной длины равняется 33, так как в маске у нас 32 бита, всего получается 33 возможных комбинации, включая комбинацию маски 0.0.0.0. Предлагаю свести все эти маски в одну таблицу и упорядочить от самой большой маски до самой маленькой, чтобы было удобно пользоваться.
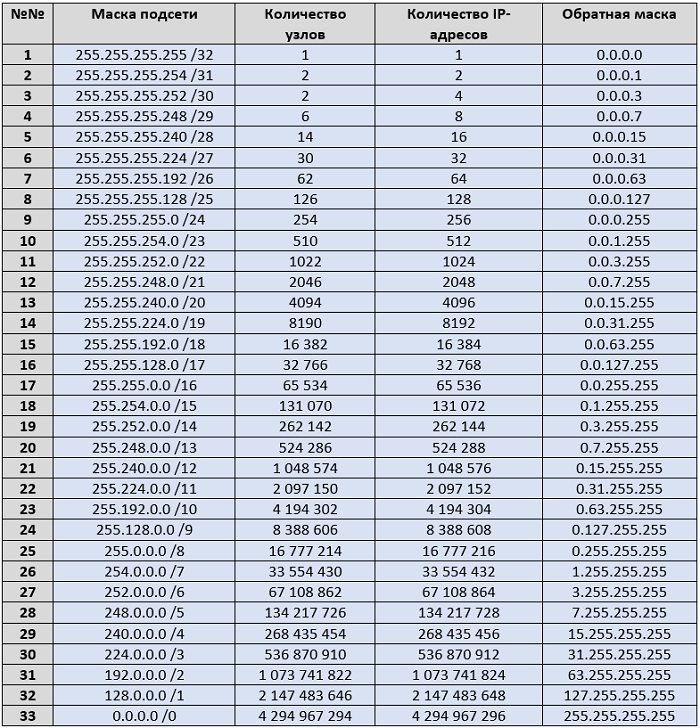
Рисунок 4.6.5 Все допустимые маски сети подсети в протоколе IPv4, а также их обратные маски
Как видите, в масках подсети прослеживается закономерность, которую легко запомнить, для этого достаточно помнить, что в маске подсети могут быть использованы числа: 255, 254, 252, 248, 240, 224, 192, 128, 0, а также не забывать, что ноль и единица не чередуется.
4.6.7 Дырявые или обратные маски (Wildcard mask)
С назначением обратных масок мы разберемся после, сейчас нам важно понимать и знать, что такие маски есть и они используются, иногда их называют дырявые маски, а в английской литературе для этого используется термин Wildcard Mask. Давайте представим, что мир перевернулся с ног на голову и маски подсети стали использовать другое правило: сначала идут все нули, которые определяют номер сети, а затем идут все единицы, которые определяют номер узла.
Для примера возьмем наш стандартный префикс 192.168.1.0/24, тогда в двоичном виде мы увидим такую картину:
[php]
IP-адрес: 11000000 10101000 00000001 00000000
Обычная маска: 11111111 11111111 11111111 00000000
Обратная маска: 00000000 00000000 00000000 11111111
[/php]
Нетрудно понять, что обратную маску мы получили из обычной маски путем применения «Логического НЕ» к каждому биту обычной маски. Если вам лень переводить числа из десятичной системы счисления в двоичную, а затем получать обратную маску, то вот пример, как получить обратную маску в десятичной системе:
[php]
Обычная маска: 255.255.240. 0
Обратная маска: 0. 0. 15.255
[/php]
Поясню. Мы от числа 255 отнимаем значение каждого октета и записываем результат в соответствии с той позицией октета, для которого октета эта операция выполнялась. Первый байт обратной маски мы получили так: 255-255 = 0, второй байт так: 255-255=0, третий байт 255-240=15, четвертый байт: 255-0=255, таким образом для маски 255.255.240.0 обратная маска будет 0.0.15.255. Чтобы из инверсной маски получить обычную маску, нужно от 255 отнять значение каждого октета.
Почему обратная маска называется дырявой? А всё дело в том, что для него нет правила: сначала только нули, а потом только единицы, в обратной маске нули и единицы могут чередоваться, и это делает ее очень мощным инструментом по отлавливанию и фильтрации трафика, проходящего через ваши маршрутизаторы.
И на самом деле у 1 и 0 в обратной маске другое назначение, здесь не зацикливаются на том, что 1 – это номер узла, а 0 – это номер сети, когда вы используете обратную маску вы говорите маршрутизатору: какие биты можно менять, а какие должны быть неизменными. Единица в обратной маске говорят о том, что значения соответствующего бита в IP-адресе может меняться, а ноль говорит о том, что соответствующий бит IP-адреса изменяться не должен. Обратные маски мы оставим до тех пор, пока не познакомимся с ACL.
Единственное, что сейчас важно отметить: Wildcard Mask нельзя использовать для разделения сетей на подсети, для этих целей можно использовать только маску подсети переменной длины.
4.6.8 Специальные маски
Заметили, что у нас есть три странные маски, которые вроде бы ни на что не годны? Сначала о масках 255.255.255.255 и 255.255.255.254, в префиксной записи они такие: /32 и /31, эти маски дают возможность создать подсети из одного и двух IP-адресов соответственно. Во-первых, сразу скажем, обе эти маски можно использовать. Более того, для префикса /31 есть специальный RFC 3021, который описывает применение данной маски. Если говорить коротко, то маску /31 можно использовать в тех ситуациях, когда в сети ровно два участника, то есть в сетях точка-точка (point-to-point, а тут можете немного почитать о физической и логической топологии компьютерной сети), современные маршрутизатору об этом «знают» и корректно работают с такими сетями. С линками point-to-point мы обязательно познакомимся, но это будет еще не скоро.
Что касается маски /32, то она тоже используется и причем очень часто. Дело всё в том, что у маршрутизаторов есть loopback интерфейсы (не IP-адреса, а именно интерфейсы), их можно нагородить целую кучу и они будут всегда доступны из вне, если будет доступен хотя бы один физический интерфейс. Поэтому для установления соединения по таким важным протоколам, как BGP, используют loopback-интерфейсы, на которые обычно задают подсети с маской /32, так же маску /32 очень удобно использовать для задания различных политик безопасности, например, вам нужно, чтобы доступ к управлению вашего сетевого устройства был только с одного конкретного IP-адреса, почему бы для этой цели не использовать маску /32.
И наконец маска, у которой все нули: 0.0.0.0. Эта маска означает просто кричит: любой IP-адрес. Такие маски чаще всего вы встретите в настройках серверов и маршрутизаторов для маршрутов по умолчанию, этот термин мы раскроем, когда будем говорить про статическую и динамическую маршрутизацию.
4.6.9 Выводы
На этот раз вместо выводов я дам одно важное пояснение к данной теме. В этой теме я очень вольно обращался с терминами VLSM и CIDR. На самом деле VLSM и CIDR — это два механизма, которые работают вместе. Причем CIDR — это механизм суммаризации маршрутов, то есть когда несколько маленьких сетей объединяются в одну бальшу (то есть CIDR это механизм по уменьшению количества единиц в маске подсети, этот механизм интересен провайдерам и крупным игрокам Интернета), а VLSM — это механизм разбиения крупных сетей на более мелкие, то есть это механизм по увеличению количества единиц в маске.
Интересная, конечно, информация, но не для всех доступная. Подскажите, как сгенерировать IP с маской в формате CIDR, если у меня динамичный IP, две первые цифры всегда одинаковые, а остальные могут меняться. Что я должна прописать в конвертере масок? с X.Y.0.0 по X.Y.255.255 и «без директивы». Правильно?
Почти так. Например, я хочу диапазон IP-адресов, в котором первых два октета будут 10.10, а последних два октета будут меняться, общая запись всех IP в этом диапазоне будет такой: 10.10.x.y.
С учетом условий выше маска будет такой: 255.255.0.0, два первых октета в маске 255 говорят о том, что первых два октета в IP-адресе не меняются, два последующих нуля в маске говорят о том, что два последних октета IP-адреса могут изменяться от 0 до 255.
Для закрепления можете любой калькулятор адресов запустить, попробовать по изменять значения.
p.s. мне не жалко было бы ваш комментарий со ссылкой в логине опубликовать, но я ее удалил, т.к. не смог открыть ваш сайт.
Большое спасибо автору! Все супер доступным языком объяснено! Только долго думала, что означена 21 =2 )) было бы классно указать 2^1 = 2
Огромное спасибо, очень грамотное и доступное объяснение