Часть 5.1: Общая информация о типах данных в SQLite3
Здравствуйте, уважаемые посетители сайта ZametkiNaPolyah.ru. Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Ранее…
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Данная публикация будет завершающей в теме обеспечения целостности данных в базах данных SQLite3. И в этой публикации мы поговорим про индексы в таблицах базы данных SQLite. На самом деле, основная задача индексов базах данных заключается в том, чтобы ускорить выборку данных, а не в том, чтобы обеспечить целостность (это скорее уже дополнительный эффект ускорения выборки). Если говорить более точно, то индексы реализуют поисковый алгоритм, например, самый простой алгоритм поиска — поиск льва в пустыне.
Часть 11.7: Индексы в базах данных SQLite. Индексация таблиц в SQLite3. Алгоритм B-дерева в базах данных
Конечно, индексы в базах данных реализованы более сложными алгоритмами, одним из самых популярных и часто используемых алгоритмов для индексов в реляционных базах данных является алгоритм работы с B-деревьями. Он получил такое большое распространение за счет своей надежности, эффективности и относительной простоты, в этом мы с вами сможем убедиться. Индексы в базах данных SQLite строятся на основе алгоритма B-дерева.
Из этой публикации вы узнаете: о том для чего нужны индексы в базах данных SQLite3 и других РСУБД; какие плюсы и какие минусы дают индексы в базах данных; как создать и удалить индексы в базе данных под управлением SQLite; попробуете поработать с индексами на примерах; разберетесь с тем, как сделать переиндексацию таблиц в SQLite3; узнаете о том, когда не стоит использовать индексы; увидите, что SQLite автоматически создает внутренние индексы для каждой таблицы (столбец ROWID), узнаете о том, как запретить SQLite создавать внутренние индексы ROWID и какие плюсы даст такой подход.
Содержание статьи:
Индексы мы отнесли к теме обеспечения целостности данных в базах данных только из-за того, что столбец PRIMARY KEY является одновременно и ограничением уровня таблицы, и индексом таблицы любой реляционной СУБД, в том числе и SQLite3. Индексы в базах данных SQLite являются объектами базы данных, это означает, что имя индекса должно быть уникальным во всей базе данных.
Так как индекс – этой объект базы данных, то к нему могут быть применены различные SQL команды. Например, команды определения данных нужны для создания и удаления индексов в базе данных, в SQLite к индексам нельзя применить команды манипуляции данными, хотя мы с легкостью можем применять эти команды к таблицам, столбцы которых являются индексами.
Основное назначение индексов в базе данных заключается в том, чтобы ускорить операцию выборки данных из базы данных. Индексы очень ускоряют выполнения команд SELECT за счет того, что реализованы они в виде B-деревьев, но об этом мы поговорим несколько ниже. Но, поскольку индексы ускоряют выборку, вернее потому, что они реализованы в виде B-деревье, индексы очень замедляют другие операции манипуляции данными:
Это происходит потому, что эти операции вносят изменения в B-дерево, которое является сбалансированным, чтобы поддерживать B-дерево в актуальном состояние SQLite проводит перерасчет узлов после каждого изменения данных в таблицах.
Если говорить просто, то при создании индекса мы создаем еще одну таблицу, в которой хранятся значения индексируемого столбца в упорядоченном виде и при этом СУБД вместо того, чтобы перебирать данные в исходной таблице, пользуются таблицей индексов, в которой хранятся ссылки на исходные таблицы, за счет этого происходит уменьшение количества операций по перебору и сравнению значений с искомым.
Сделаем выводы: индексы в базах данных ускоряют запросы на выборку данных за счет уменьшения операций по сравнению значений, но замедляют другие операции манипуляции с данными.
Индексы очень сильно ускоряют выборку данных из базы данных при помощи команды SELECT, но в то же время индексы замедляют работу других операторов манипуляции данными. Давайте посмотрим, как создавать индексы для таблиц базы данных под управлением SQLite. Хотя мы уже много раз создавали индексы в базах данных, когда объявляли ограничение первичного ключа для столбца – PRIMARY KEY (ключи и ключевые атрибуты).
Ограничение первичного ключа – это ограничение уровня таблицы, которое используется для обеспечения целостности данных в базах данных, но в то же время столбец PRIMARY KEY–это индекс в базе данных, который заметно ускоряет выборку данных.
А теперь давайте рассмотрим синтаксис создания индексов в базах данных SQlite3:
[php]
CREATE INDEX IF NOT EXISTS dbname.ixname ON tblname (columnname) WHERE…
[/php]
SQLite имеет гибкий синтаксис создания индексов: чтобы сказать, что мы хотим создать объект базы данных, нужно использовать команду CREATE, далее мы указываем, какой объект базы данных мы хотим создать, в нашем случае INDEX. После чего идет необязательная проверка на существование IF NOT EXISTS. Проверка нужна, если вы не уверены в том, что индекс существует.
Если вы указали ключевую фразу IF NOT EXISTS, то SQLite сперва проверит имя индекса на уникальность и если в базе данных есть индекс с таким именем, то выдаст предупреждение, а не ошибку. После проверки идет имя индекса, вместо которого можно использовать квалификатор или полное имя индекса с указанием базы данных.
Далее идет ключевое слово ON, после которого указывается имя таблицы, для которой будет создан индекс. После имени таблицы в круглых скобках указывается имя столбца этой таблицы, который будет проиндексирован, заметьте, что индексируемых столбцов можем быть несколько, в этом случае они разделяются запятой.
После имени столбца можно использовать клаузулу WHERE, которая позволяет задать определенные условия для создания индекса.
Мы упоминали о том, что SQLite позволяет создавать несколько индексов для одной таблицы в базе данных, давайте разберемся с синтаксисом создания нескольких индексов для одной таблицы, такие индексы еще называют композитными:
[php]
CREATE INDEX IF NOT EXISTS dbname.ixname ON tblname (columnname1, columnname2);
[/php]
Создание нескольких индексов для одной таблицы ничем принципиально не отличается от создания одного индекса: мы просто перечисляем столбцы в круглых скобках, которые будут проиндексированы.
Но SQLite дает возможность создавать индексы не для всех значений столбца (не для всех строк в таблице), а только частичные индексы. Частичные индексы создаются путем наложения определенных условий на значения, хранящиеся в столбце при помощи клаузулы WHERE:
[php]
CREATE INDEX ind_name
ON table1 (column_name)
WHERE column_name IS NOT NULL;
[/php]
Мы знаем, что в SQLite значение с типом данных NULL всегда уникально, так как значение с классом данных NULL не равно даже другому NULL, в данном случае будет создан частичный индекс для всех строк столбца, кроме тех строк, у которых в столбце column_name хранится значение NULL.
Мы поняли те преимущества, которые дают индексы в базах данных и научились создавать индексы в базах данных. Теперь пора посмотреть, как можно удалить индексы из базы данных. Мы знаем, что индекс — это объект базы данных, как, например таблица или триггер. Поэтому операция удаления индекса из базы данных выполняется той же командой, что и удаление таблицы из базы данных:
[php]
DROP INDEX IF EXIST dbname.tblname;
[/php]
Поскольку индекс – это объект, его имя должно быть уникальным во всей базе данных, но бывают случаи, когда вы работаете одновременно с несколькими базами данных, тогда индексы можно удалить с использованием квалификатора или полного имени индекса. Конструкцией IF EXISTS можно проверить существование индекса перед его удалением, тогда, если индекса с таким именем нет, SQLite выдаст предупреждение, в противном случае будет ошибка. Сам запрос на удаление индекса начинается с команды DROP, а затем идет ключевая фраза INDEX, которая сообщает SQLite3 о том, что мы хотим удалить именно индекс, а не какой-то другой объект базы данных.
Давайте посмотрим несколько примеров по созданию индексов в базах данных SQLite. В последствии мы посмотрим, что индексы действительно ускоряют выборку данных, когда будем рассматривать выборку данных из базы данных.
Давайте создадим таблицу в базе данных, воспользовавшись командой CREATE:
[php]
CREATE TABLE table1 (
a TEXT NOT NULL,
b TEXT NOT NULL,
c INTEGER
);
[/php]
А теперь создадим индекс для таблицы table1, воспользовавшись опять же командой CREATE:
[php]
CREATE INDEX ind_col_a ON table1 (a);
[/php]
Мы создали индекс и можем убедиться в том, что индекс для таблицы table1 действительно существует и в том, что это столбец «а», воспользуемся командой PRAGMA.
[php]
PRAGMA index_list (table1);
seq name unique origin partial
0 ind_col_a 0 c 0
[/php]
Давайте добавим данные в нашу таблицу, воспользовавшись командой INSERT:
[php]
INSERT INTO table1 (a, b, c)
VALUES (‘Текст 1’, ‘Текст 1’, 1);
INSERT INTO table1 (a, b, c)
VALUES (‘Текст 2’, ‘Текст 2’, 3);
INSERT INTO table1 (a, b, c)
VALUES (‘Текст 3’, ‘Текст 3’, 3);
[/php]
Еще одним способом проверки того, что индекс был действительно создан является dot-команда .indices или, если нужно знать индексы для таблицы table1: .indices table1. Чтобы получить информацию о созданном индексе, воспользуйтесь следующим запросом SELECT:
[php]
SELECT * FROM sqlite_master WHERE type = 'index';
[/php]
Но SQLite позволяет создавать индексы с ограничение уникальности, давайте создадим индекс в базе данных, значения которого должны быть уникальными, обратите внимание: индекс не будет являться ключевым атрибутом таблицы, он будет просто уникальным:
[php]
CREATE UNIQUE INDEX ind_col_b ON table1 (b);
INSERT INTO table1 (a, b, c)
VALUES (‘Текст 3’, ‘Текст 3’, 3);
[/php]
Команда INSERT не будет выполнена, так как она нарушает ограничение уникальности значений в столбце. В SQLite индексы можно удалять, для удаления индекса из базы данных служит команда DROP, этой командой мы можем удалять таблицы из базы данных и другие объекты базы данных:
[php]
DROP INDEX ind_col_b;
DROP INDEX ind_col_a;
[/php]
Оба индекса для таблицы table1 были удалены. Давайте теперь посмотрим пример создания композитного индекса или, как создать индекс из значений нескольких столбцов таблицы базы данных:
[php]
CREATE UNIQUE INDEX ind_col_ab ON table1 (a, b);
[/php]
Мы создали составной индекс, значения которого будут состоять из значений двух столбцов: «а» и «b».
В базах данных SQLit eнельзя применять к индексу команду ALTER, то есть никаких изменений в структуру индекса вы внести не сможете. Поэтому для переименования индекса в базах данных SQLite вам необходимо сперва удалить старый индекс, а затем создать новый индекс для таблицы базы данных.
Но иногда бывает необходимость сделать переиндексацию таблиц в базах данных SQLIte3. Переиндексация полезна в том случае, когда изменился порядок сортировки данных в столбце, который объявлен, как индекс таблицы. Общий синтаксис переиндексации данных в базах данных под управлением SQLite выглядит так:
[php]
REINDEX dbname.tblname
— допустим и такой вариант
REINDEX dbname.indexname
[/php]
У нас есть два варианта переиндексации таблиц, если мы указываем имя таблицы, то SQLite сделает переиндексацию для всех столбцов таблицы, которые указаны, как индекс. Если мы делаем переиндексацию, указывая имя индекса, то значения последовательность будет удалена и сформирована заново для конкретного индекса.
Индексы – очень мощный и полезный инструмент в базах данных, в том числе и в базах данных под управлением SQLite. Индексы в базах данных создаются для того, чтобы ускорить операции выборки данных, обычно реляционные СУБД создают отдельные таблицы, в которых они хранят значения проиндексированных столбцов в упорядоченном виде, поэтому создание индексов – это всегда расширение и увеличение ваших баз данных.
Индексы удобны и хороши, но бывают ситуации, когда индексы не стоит использовать, например:
У каждой таблицы базы данных SQLite по умолчанию есть внутренний индекс, который называет ROWID. Иногда этот индекс совпадает с первичным ключом таблицы PRIMARY KEY, иногда не совпадает, но ROWID есть у каждой таблицы. Если говорить просто и понятно, то ROWID – это дополнительный столбец, который есть у любой таблицы SQLiteи является индексом для данной таблицы.
Помимо того, что ROWID – это индекс, это еще один способ поддержание целостности данных. Давайте разберемся с индексом ROWID в базах данных SQLite. ROWID–это 64-разрядное число, которое однозначно идентифицирую любую строку в базе данных SQLite.
Особенностью баз данных SQLite является то, что все строки базы данных хранятся в виде B-дерева (многие СУБД используют алгоритм B-дерева). Если говорить коротко и абстрактно, то B-дерево – это сбалансированное и очень ветвистое дерево, которое очень сильно ускоряет выборку данных.
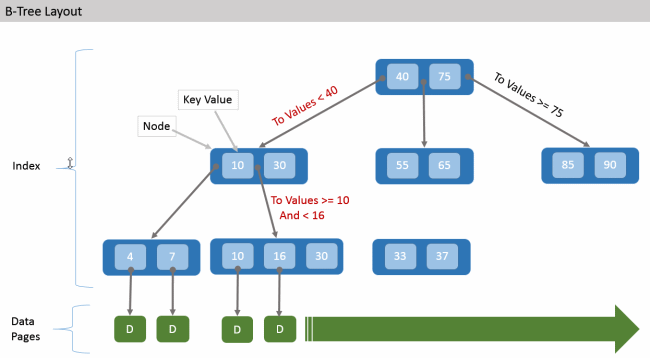
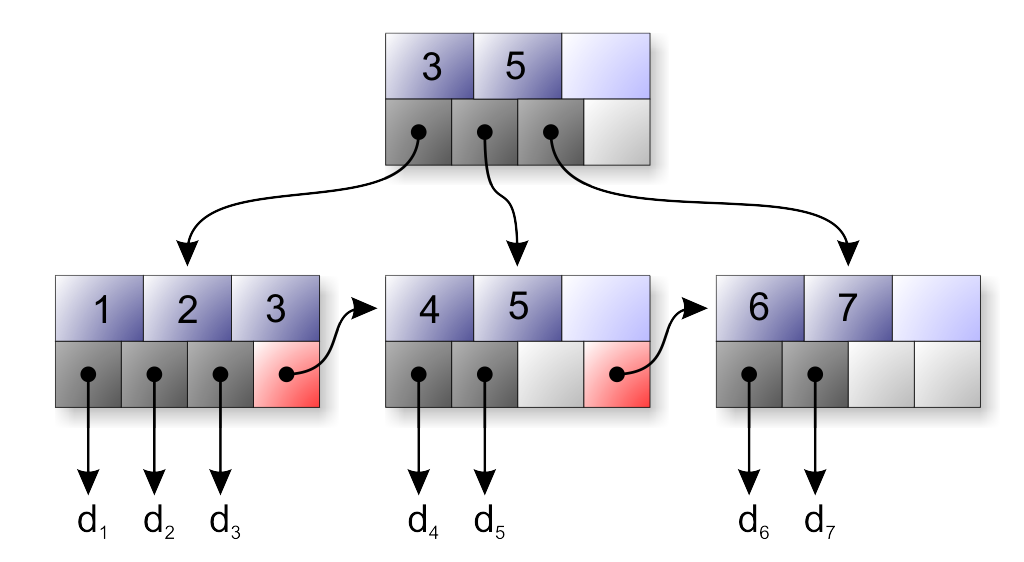
Давайте разберемся с тем, что такое B-дерево и поймем, как работают индексы в базах данных SQLite и других реляционных СУБД. Для начала предложу вам взглянуть на изображение ниже, оно показывает структуру B-дерева, а, соответственно, и структуру индексов в базе данных.
Структура индексов в базе данных SQLite. Структура B-дерева
Мы видим, что структура B-дерева ветвистая, каждый лепесток дерева – это узел, в базах данных SQLite и других реляционных базах данных каждый узел – это таблица. Верхняя таблица на рисунке – это корень B-дерева. B-дерево называют сбалансированным, потому что длинна пути от корня до любых двух узлов одного уровня совпадают.
Корень B-дерева – это таблица справочник, в которой записываются ссылки на другие справочники, справочники второго уровня могут тоже ссылаться на другие справочники, а те в свою очередь хранят в себе ссылки на какие-то данные, на самом деле, глубина B-дерева может быть очень большой (уровней может быть много).
Когда мы выполняем команду SELECT СУБД начинает делать перебор данных, сравнивая указанное значение со значениями, которые хранятся в базе данных, если бы в базе данных было миллион строк, то СУБД перебирала бы миллион строк, либо пока не закончились строки, либо пока не было бы найдено искомое значение.
B-деревья как раз-таки помогают нам избежать тупого перебора строк и сокращают количество проверок во много раз, всё зависит от количества строк в базе данных.
Давайте попробуем привести простой пример B-дерева, чтобы понять суть индексов в базах данных. Корень дерева можно представить, как таблицу с двумя колонками, например, таблица-алфавит. Один столбец – столбец ID, второй столбец – столбец букв алфавита. Буква – это ссылка на таблицу справочник, например, если корень алфавит, то, возможно для корня у нас было бы 33 справочника структура справочников была бы примерно одинакова, например, справочник для буквы А:
[php]
ID DATA
1 аа
2 аб
3 ав
4 аг
[/php]
И так далее, пока не переберем 33 комбинации. Для буквы Г справочник бы выглядел так:
[php]
ID DATA
1 га
2 гб
3 гв
4 гг
[/php]
И так пока не переберем 33 комбинации. У этих справочников второго уровня могли бы быть справочники третьего уровня и так далее, пока не доберемся до данных. А теперь представим, что нам нужно найти слово «Яблоко» в неупорядоченном списке из хотя бы 10000 слов. Как это можно реализовать на языке программирования, например, мы можем запустить цикл, в котором сперва упорядочим значения по алфавиту, а потом запустить поиск, например, используя алгоритм поиска льва в пустыне, но это не самая эффективная затея в плане поиска данных.
Гораздо более быстро работает алгоритм B-деревьев. В каждый узел B-дерева данные записываются уже в строго упорядоченном виде и при добавлении новых значений SQLite или любая другая СУБД начинает пересчитывать пути к данным, за счет этого операции добавления и модификации данных в базах данных становятся более дорогими, а запросы на выборку становятся более дешевыми.
Давайте попробуем найти слово «Яблоко», используя алгоритм B-дерево. У нас есть корень, в котором алфавит хранится в отсортированном виде. Мы знаем, что буква Я последняя буква в алфавите и напрямую обращаемся к ячейке Я корневого справочника.
[php]
ID DATA
1 а
2 б
3 в
... ...
33 я
[/php]
Эта ячейка является ссылкой на справочник второго уровня, в котором значения тоже отсортированы:
[php]
ID DATA
1 яа
2 яб
3 яв
... ...
33 яя
[/php]
Таким образом нам нужно перебрать только две строки: сравниваем «Яб» с яа, понимаем, что это не то, сравниваем «Яб» с яб и понимаем, что это то, что мы искали, яб из таблицы справочника является ссылкой на таблицу, в которой хранятся все слова, начинающиеся с яб. В этойтаблицt значений слова уже отсортированы, например:
[php]
ID DATA
1 Ябеда
2 Яблоко
3 Яблоня
[/php]
И начинаем перебирать, понимаем, что слово Ябеда нам не подходит, но второе значение совпадает с нашим – успех. Таким образом мы смогли найти слово Яблоко в списке из 10000 слов, проверив четыре значения.
Конечно, пример абстрактный, но он демонстрирует мощь B-деревьев при поиске данных в базе данных, а также показывает то, почему операция добавления данных в базу данных при наличии индексов становится более дорогой и затратной: СУБД должна пересчитать узлы при добавлении новых данных или их изменении.
Мы несколько отошли от внутреннего индекса базы данных SQLite ROWID, чтобы понять принцип его работы и принцип работы индексов в базах данных. Давайте теперь проверим, что SQLite действительно создает столбец ROWID.
Создадим таблицу в базе данных при помощи команды CREATE:
[php]
CREATE TABLE table1 (a, b ,c ,d);
[/php]
В этой таблице 4 столбца: нет ни одного индекса и нет первичного ключа, давайте добавим данный в таблицу, для этого есть команда INSERT:
[php]
INSERT INTO table1 (a, b, c , d)
VALUES (1, 2, 3, 4);
INSERT INTO table1 (a, b, c , d)
VALUES (1, 2, 3, 4);
INSERT INTO table1 (a, b, c , d)
VALUES (1, 2, 3, 4);
INSERT INTO table1 (a, b, c , d)
VALUES (1, 2, 3, 4);
[/php]
Мы добавили четыре строки в таблицу базы данных SQLite, посмотри содержимое таблицы:
[php]
sqlite> select*from table1;
a|b|c|d
1|2|3|4
1|2|3|4
1|2|3|4
1|2|3|4
[/php]
Мы включили имена столбцов при помощи специальной SQLite команды .headers и заметили, что никакого столбца ROWID в таблице нет. Всё дело в том, что SQLite не показывает этот столбец, если не обращаться к нему по имени, давайте изменим наш запрос SELECT:
[php]
SELECT rowid, a, b, c, d FROM table1;
rowid|a|b|c|d
1|1|2|3|4
2|1|2|3|4
3|1|2|3|4
4|1|2|3|4
[/php]
Теперь мы видим, что в таблице базы данных SQLite есть столбец ROWID, а соответственно, и внутренний индекс в таблице SQLite действительно есть и он создается автоматически. Но, мы можем создавать первичный ключ для таблицы и, бывают ситуации, когда первичный ключ совпадает со значение ROWID в таблицах SQLite. Чтобы столбец PRIMARY KEY совпадал с ROWID, вам нужно создавать таблицы одним из трех способов, указанных ниже:
[php]
CREATE TABLE table1 (x INTEGER PRIMARY KEY ASC, y, z);
CREATE TABLE table2 (x INTEGER, y, z, PRIMARY KEY (x ASC));
CREATE TABLE table3 (x INTEGER, y, z, PRIMARY KEY (x DESC));
[/php]
Обратите внимание: если столбец PRIMARY KEY объявить как-нибудь по-другому, то значения PRIMARY KEY и ROWID совпадать не будут. Значение столбца ROWID вы можете менять при помощи команды UPDATE, как и другие значения в таблице базы данных. Но помните о правилах уникальности и вечности, которые свойственны для ключевых атрибутов и необходимы для обеспечения целостности данных в базе данных, так как PRIMARY KEY–это ограничение уровня таблицы, то мы вправе считать, что внутренний индекс SQLite ROWID–это ограничение уровня таблицы.
В SQLite можно создавать таблицы без столбца ROWID, то есть без внутреннего индекса. Такой подход несет незначительные плюсы: иногда это ускоряет выборку данных из базы данных и немного уменьшает объем базы данных. Если вы решили создать таблицу без ROWID в SQLite, то вам необходимо сделать две вещи: во-первых, у таблицы должен быть обязательно первичный ключ, во-вторых, вам необходимо использовать ключевую фразу WITHOUT ROWID.
Давайте создадим таблицу без столбца ROWID, воспользовавшись конструкцией WITHOUT ROWID:
[php]
CREATE TABLE IF NOT EXISTS wordcount (
word TEXT PRIMARY KEY,
cnt INTEGER
) WITHOUT ROWID;
[/php]
Теперь у таблицы не будет столбца ROWID. Еще одной особенностью таблиц WITHOUT ROWID является то, что ограничение уровня столбца AUTOINCREMENT работать не будет. Первичный ключ таблицы WITHOUT ROWID ни при каких обстоятельствах не может иметь значение NULL, если вы попробуете добавить NULL в столбец PRIMARY KEY таблицы WITHOUT ROWID, то SQLite выдаст ошибку.
Из-за особенностей работы таблиц WITHOUT ROWID, разработчики SQLiteрекомендуют использовать такие таблицы в тех случаях, когда:
Если вы проектируете базу данных и хотите ее оптимизировать, то вам не стоит задумываться о том, какие таблицы использовать: ROWID или WITHOUT ROWID, на этапе разработки и проектирования. Тесты лучше всего проводить после того, как база данных будет спроектирована и реализована. Так как никаких отличий между таблицами с ROWID и без нет, за исключением тех, что описаны выше, нет.

Спасибо, очень доступно описали работу индексов в РСУБД и, очень интересно написали про B-деревья. Всё по полочкам расставили!
Кирилл, доброго времени суток!
Я правильно понимаю, что если мне не надо делать выборку из базы данных, то индексы лучше отключить? Только у меня база на MySQL крутится, а не на SQLite3, как вы пишите!
Приветствую!
Тут нужно исходить из ситуации: если действительно вам не нужна поддержка целостности данных в базах данных и нет необходимости делать запросы SELECT, то индексы лучше не создавать, так как это дополнительно занятое место.